MariaDB Galera Cluster 介绍 MariaDB 集群是 MariaDB 同步多主机集群。它仅支持 XtraDB/ InnoDB 存储引擎(虽然有对 MyISAM 实验支持 - 看 wsrep_replicate_myisam 系统变量)。
主要功能:
同步复制
真正的 multi-master,即所有节点可以同时读写数据库
自动的节点成员控制,失效节点自动被清除
新节点加入数据自动复制
真正的并行复制,行级
用户可以直接连接集群,使用感受上与MySQL完全一致
优势:
因为是多主,所以不存在Slavelag(延迟)
不存在丢失事务的情况
同时具有读和写的扩展能力
更小的客户端延迟
节点间数据是同步的,而 Master/Slave 模式是异步的,不同 slave 上的 binlog 可能是不同的
技术:
Galera 集群的复制功能基于 Galeralibrary 实现,为了让 MySQL 与 Galera library 通讯,特别针对 MySQL 开发了 wsrep API。
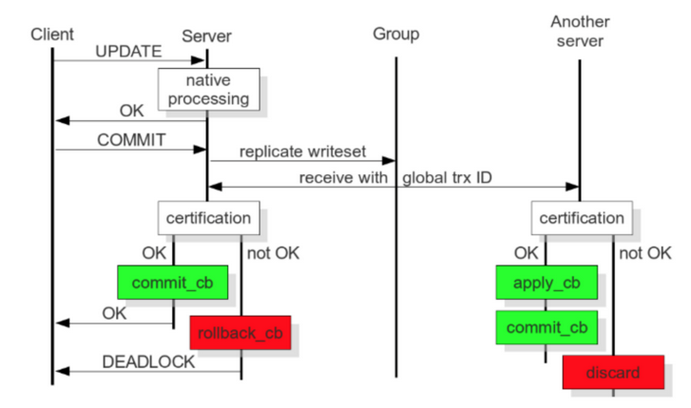
Galera 插件保证集群同步数据,保持数据的一致性,靠的就是可认证的复制,工作原理如下图:
当客户端发出一个 commit 的指令,在事务被提交之前,所有对数据库的更改都会被write-set收集起来,并且将 write-set 纪录的内容发送给其他节点。
write-set 将在每个节点进行认证测试,测试结果决定着节点是否应用write-set更改数据。
如果认证测试失败,节点将丢弃 write-set ;如果认证测试成功,则事务提交。
MariaDB Galera Cluster部署 环境 三台服务器,CentOS7
服务器名称
IP地址
node1
10.10.10.4
node2
10.10.10.5
node3
10.10.10.6
系统初始化配置 服务器名称
1 2 3 hostnamectl set -hostname node1 hostnamectl set -hostname node2 hostnamectl set -hostname node3
时区
1 timedatectl set -timezone Asia/Shanghai
系统源
1 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
关闭selinux
1 2 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenforce 0
关闭自带防火墙
1 2 systemctl stop firewalld systemctl disable firewalld
添加MariaDB的yum源 1 2 3 4 5 6 7 cat >/etc/yum.repos.d/MariaDB.repo << EOF [mariadb] name = MariaDB baseurl = http://mirrors.ustc.edu.cn/mariadb/yum/10.1/centos7-amd64 gpgkey=http://mirrors.ustc.edu.cn/mariadb/yum/RPM-GPG-KEY-MariaDB gpgcheck=1 EOF
安装软件包 1 yum install mariadb mariadb-server mariadb-common galera rsync
数据库初始化 在node1上执行
1 2 3 systemctl start mariadb mysql_secure_installation systemctl stop mariadb
mysql_secure_installation 这一步有交互,做一些配置
修改galera相关配置 三台服务器编辑文件 /etc/my.cnf.d/server.cnf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ... [galera] wsrep_on=ON wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_name=galera_cluster wsrep_cluster_address="gcomm://10.10.10.4,10.10.10.5,10.10.10.6" wsrep_node_name=10.10.10.4 wsrep_node_address=10.10.10.4 binlog_format=row default_storage_engine=InnoDB innodb_autoinc_lock_mode=2 log -error=/var/log /mariadb.log...
wsrep_node_name 和 wsrep_node_address 改成本机ip
启动MariaDB Galera Cluster服务 node1上执行 1 service mysql start --wsrep-new-cluster
或
出现 ready for connections ,证明启动成功。
node2和node3上执行 确认node2和node3的mariadb服务启动成功后,将node1的mariadb进程kill,再重新启动mariadb 1 2 ps -ef|grep mysqld|grep -v grep|awk '{print $2}'|xargs kill -9 systemctl start mariadb
验证集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 #显示集群节点数 MariaDB [(none)]> show status like 'wsrep_cluster_size'; +--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 3 | +--------------------+-------+ 1 row in set (0.00 sec) #连接状态 MariaDB [(none)]> show status like 'wsrep_connected'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | wsrep_connected | ON | +-----------------+-------+ 1 row in set (0.00 sec) #显示节点ip MariaDB [(none)]> show status like 'wsrep_incoming_addresses' ; +--------------------------+-------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------+ | wsrep_incoming_addresses | 10.10.10.5:3306,10.10.10.6:3306,10.10.10.4:3306 | +--------------------------+-------------------------------------------------+ 1 row in set (0.00 sec) #集群同步状态 MariaDB [(none)]> show status like 'wsrep_local_state_comment'; +---------------------------+--------+ | Variable_name | Value | +---------------------------+--------+ | wsrep_local_state_comment | Synced | +---------------------------+--------+ 1 row in set (0.00 sec) 集群相关状态参数 MariaDB [(none)]> show status like 'wsrep_%'; +------------------------------+-------------------------------------------------+ | Variable_name | Value | +------------------------------+-------------------------------------------------+ | wsrep_apply_oooe | 0.000000 | | wsrep_apply_oool | 0.000000 | | wsrep_apply_window | 0.000000 | | wsrep_causal_reads | 0 | | wsrep_cert_deps_distance | 0.000000 | | wsrep_cert_index_size | 0 | | wsrep_cert_interval | 0.000000 | | wsrep_cluster_conf_id | 3 | | wsrep_cluster_size | 3 | | wsrep_cluster_state_uuid | 58032a2b-10f3-11ea-99a5-33ce1b994a28 | | wsrep_cluster_status | Primary | | wsrep_cluster_weight | 3 | | wsrep_commit_oooe | 0.000000 | | wsrep_commit_oool | 0.000000 | | wsrep_commit_window | 0.000000 | | wsrep_connected | ON | | wsrep_desync_count | 0 | | wsrep_evs_delayed | | | wsrep_evs_evict_list | | | wsrep_evs_repl_latency | 0/0/0/0/0 | | wsrep_evs_state | OPERATIONAL | | wsrep_flow_control_paused | 0.000000 | | wsrep_flow_control_paused_ns | 0 | | wsrep_flow_control_recv | 0 | | wsrep_flow_control_sent | 0 | | wsrep_gcomm_uuid | 5800c431-10f3-11ea-9506-92ff7d3b693e | | wsrep_incoming_addresses | 10.10.10.5:3306,10.10.10.6:3306,10.10.10.4:3306 | | wsrep_last_committed | 0 | | wsrep_local_bf_aborts | 0 | | wsrep_local_cached_downto | 18446744073709551615 | | wsrep_local_cert_failures | 0 | | wsrep_local_commits | 0 | | wsrep_local_index | 2 | | wsrep_local_recv_queue | 0 | | wsrep_local_recv_queue_avg | 0.142857 | | wsrep_local_recv_queue_max | 2 | | wsrep_local_recv_queue_min | 0 | | wsrep_local_replays | 0 | | wsrep_local_send_queue | 0 | | wsrep_local_send_queue_avg | 0.000000 | | wsrep_local_send_queue_max | 1 | | wsrep_local_send_queue_min | 0 | | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | | wsrep_local_state_uuid | 58032a2b-10f3-11ea-99a5-33ce1b994a28 | | wsrep_open_connections | 0 | | wsrep_open_transactions | 0 | | wsrep_protocol_version | 9 | | wsrep_provider_name | Galera | | wsrep_provider_vendor | Codership Oy <[email protected] > | | wsrep_provider_version | 25.3.28(r3875) | | wsrep_ready | ON | | wsrep_received | 7 | | wsrep_received_bytes | 694 | | wsrep_repl_data_bytes | 0 | | wsrep_repl_keys | 0 | | wsrep_repl_keys_bytes | 0 | | wsrep_repl_other_bytes | 0 | | wsrep_replicated | 0 | | wsrep_replicated_bytes | 0 | | wsrep_thread_count | 2 | +------------------------------+-------------------------------------------------+
MariaDB Galera Cluster的自启动 在实际使用中发现一个问题,Galera集群启动时必须按照一个特定的规则启动,规则如下:
如果集群从来没有启动过(3个节点上都没有/var/lib/mysql/grastate.dat文件),则必要由其中一个节点以--wsrep-new-cluster参数启动,另外两个节点正常启动即可
如果集群以前启动过,则参考/var/lib/mysql/grastate.dat,找到safe_to_bootstrap为1的节点,在该节点上以--wsrep-new-cluster参数启动,另外两个节点正常启动即可
如果集群以前启动过,但参考/var/lib/mysql/grastate.dat,找不到safe_to_bootstrap为1的节点(一般是因为mariadb服务非正常停止造成),则在3个节点中随便找1个节点,将/var/lib/mysql/grastate.dat中的safe_to_bootstrap修改为1,再在该节点上以--wsrep-new-cluster参数启动,另外两个节点正常启动即可
从以上3种场景可知,正常情况下很难保证mariadb galera cluster可以无人值守地完成开机自启动。
最后写了个脚本,放在3个虚拟机上面,解决了这个问题。脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 cat /usr/local/bin/mariadb_cluster_helper.sh #!/bin/bash GRASTATE_FILE=/var/lib/mysql/grastate.dat WSREP_NEW_CLUSTER_LOG_FILE=/tmp/wsrep_new_cluster.log # 如果启动mariadb超过10秒还没返回0,则认为失败了 START_MARIADB_TIMEOUT=10 # 以--wsrep-new-cluster参数启动,超过5次检查,发现仍没有其它节点加入集群,则认为此路不通 SPECIAL_START_WAIT_MAX_COUNT=5 # 得到本机IP MY_IP=$(grep 'wsrep_node_address' /etc/my.cnf.d/server.cnf | awk -F '=' '{print $2}') # 杀掉mysqld进程 function kill_mysqld_process() { (ps -ef|grep mysqld|grep -v grep|awk '{print $2}'|xargs kill -9) &>/dev/null } # 正常启动mariadb function start_mariadb_normal(){ # 首先确保safe_to_bootstrap标记为0 sed -i 's/^safe_to_bootstrap.*$/safe_to_bootstrap: 0/' $GRASTATE_FILE timeout $START_MARIADB_TIMEOUT systemctl start mariadb &> /dev/null return $? } # 以--wsrep-new-cluster参数启动mariadb function start_mariadb_special(){ # 首先确保safe_to_bootstrap标记为1 sed -i 's/^safe_to_bootstrap.*$/safe_to_bootstrap: 1/' $GRASTATE_FILE # 以--wsrep-new-cluster参数启动mariadb /usr/sbin/mysqld --user=mysql --wsrep-new-cluster &> $WSREP_NEW_CLUSTER_LOG_FILE & disown $! try_count=0 # 循环检查 while [ 1 ]; do # 如果超过SPECIAL_START_WAIT_MAX_COUNT次检查,仍没有其它节点加入集群,则认为此路不通,尝试正常启动,跳出循环 if [ $try_count -gt $SPECIAL_START_WAIT_MAX_COUNT ] ; then kill_mysqld_process start_mariadb_normal return $? fi new_joined_count=$(grep 'synced with group' /tmp/wsrep_new_cluster.log | grep -v $MY_IP|wc -l) exception_count=$(grep 'exception from gcomm, backend must be restarted' $WSREP_NEW_CLUSTER_LOG_FILE | wc -l) # 如果新加入的节点数大于0,则认为集群就绪了,可正常启动了,跳出循环 # 如果运行日志中发现了异常(两个节点都以--wsrep-new-cluster参数启动,其中一个会报错),则认为此路不通,尝试正常启动,跳出循环 if [ $new_joined_count -gt 0 ] || [ $exception_count -gt 0 ] ; then kill_mysqld_process start_mariadb_normal return $? else try_count=$(( $try_count + 1 )) fi sleep 5 done } # 首先杀掉mysqld进程 kill_mysqld_process ret=-1 # 如果safe_to_bootstrap标记为1,则立即以--wsrep-new-cluster参数启动 if [ -f $GRASTATE_FILE ]; then safe_bootstrap_flag=$(grep 'safe_to_bootstrap' $GRASTATE_FILE | awk -F ': ' '{print $2}') if [ $safe_bootstrap_flag -eq 1 ] ; then start_mariadb_special ret=$? else start_mariadb_normal ret=$? fi else start_mariadb_normal ret=$? fi # 随机地按某种方式启动,直到以某种方式正常启动以止;否则杀掉mysqld进程,随机休息一会儿,重试 while [ $ret -ne 0 ]; do kill_mysqld_process sleep_time=$(( $RANDOM % 10 )) sleep $sleep_time choice=$(( $RANDOM % 2 )) ret=-1 if [ $choice -eq 0 ] ; then start_mariadb_special ret=$? else start_mariadb_normal ret=$? fi done # 使上述脚本开机自启动 chmod +x /usr/local/bin/mariadb_cluster_helper.sh chmod +x /etc/rc.d/rc.local echo ' /usr/local/bin/mariadb_cluster_helper.sh &> /var/log/mariadb_cluster_helper.log &' >> /etc/rc.d/rc.local
然后3个节点终于可以开机自启动自动组成集群了。
keepalived+haproxy+clustercheck 为了保证mariadb galera集群的高可用,可以使用haproxy进行请求负载均衡,同时为了实现haproxy的高可用,可使用keepalived实现haproxy的热备方案。keepalived实现haproxy的热备方案可参见之前的博文 。这里重点说一下haproxy对mariadb galera集群的请求负载均衡。
这里使用了 https://github.com/olafz/percona-clustercheck 所述方案,使用外部脚本在应用层检查galera节点的状态。
首先在mariadb里进行授权:
1 GRANT PROCESS ON *.* TO 'clustercheckuser' @'%' IDENTIFIED BY 'clustercheckpassword!'
下载检测脚本:
1 2 wget -O /usr/bin/clustercheck https://raw.githubusercontent.com/olafz/percona-clustercheck/master/clustercheck chmod +x /usr/bin/clustercheck
准备检测脚本用到的配置文件:
1 2 3 4 5 MYSQL_USERNAME="clustercheckuser" MYSQL_PASSWORD="clustercheckpassword!" MYSQL_HOST="$db_ip" MYSQL_PORT="3306" AVAILABLE_WHEN_DONOR=0
测试一下监控脚本:
使用xinetd暴露http接口,用于检测galera节点同步状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cat > /etc/xinetd.d/mysqlchk << EOF service mysqlchk { disable = no flags = REUSE socket_type = stream port = 9200 wait = no user = nobody server = /usr/bin/clustercheck log_on_failure += USERID only_from = 0.0.0.0/0 per_source = UNLIMITED } EOF service xinetd restart
测试一下暴露出的http接口:
1 2 3 curl http://127.0.0.1:9200 Galera cluster node is synced. # synced Galera cluster node is not synced # un-synced
最后在/etc/haproxy/haproxy.cfg里配置负载均衡:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ... frontend vip-mysql bind $vip:3306 timeout client 900m log global option tcplog mode tcp default_backend vms-mysql backend vms-mysql option httpchk stick-table type ip size 1000 stick on dst balance leastconn timeout server 900m server mysql1 $db1_ip:3306 check inter 1s port 9200 backup on-marked-down shutdown-sessions maxconn 60000 server mysql2 $db2_ip:3306 check inter 1s port 9200 backup on-marked-down shutdown-sessions maxconn 60000 server mysql2 $db3_ip:3306 check inter 1s port 9200 backup on-marked-down shutdown-sessions maxconn 60000 ...
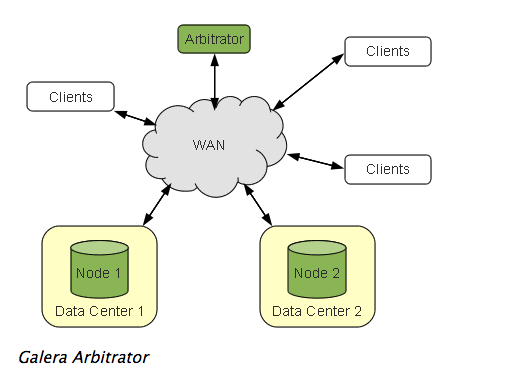
搭配galera仲裁服务 官方也提到gelera集群最少要三节点部署,但每增加一个节点,要付出相应的资源,因此也可以最少两节点部署,再加上一个galera仲裁服务。
The recommended deployment of Galera Cluster is that you use a minimum of three instances. Three nodes, three datacenters and so on.
In the event that the expense of adding resources, such as a third datacenter, is too costly, you can use Galera Arbitrator . Galera Arbitrator is a member of the cluster that participates in voting, but not in the actual replication
这种部署模式有两个好处:
使集群刚好是奇数节点,不易产生脑裂。
可能通过它得到一个一致的数据库状态快照,可以用来备份。
这种部署模式的架构图如下:
部署方法也比较简单:
1 2 3 4 5 6 echo 'GALERA_NODES="10.211.55.6:4567 10.211.55.7:4567" # 这里是两节点的地址 GALERA_GROUP="galera_cluster" # 这里的group名称保持与两节点的wsrep_cluster_name属性一致 LOG_FILE="/var/log/garb.log" ' > /etc/sysconfig/garbsystemctl start garb
测试一下效果。
首先看一下两节点部署产生脑裂的场景。
1 2 3 4 5 6 7 8 9 10 11 12 systemctl stop garb iptables -A OUTPUT -d 10.211.55.6 -j DROP iptables -A OUTPUT -d 10.211.55.9 -j DROP mysql -e "show status like 'wsrep_local_state_comment'" +---------------------------+-------------+ | Variable_name | Value | +---------------------------+-------------+ | wsrep_local_state_comment | Initialized | +---------------------------+-------------+
再试验下有仲裁节点参与的场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 systemctl start garb mysql -e "show status like 'wsrep_cluster_size'" +---------------------------+-------------+ | Variable_name | Value | +---------------------------+-------------+ | wsrep_cluster_size | 3 | +---------------------------+-------------+ iptables -A OUTPUT -d 10.211.55.6 -j DROP iptables -A OUTPUT -d 10.211.55.9 -j DROP mysql -e "show status like 'wsrep_local_state_comment'" +---------------------------+-------------+ | Variable_name | Value | +---------------------------+-------------+ | wsrep_local_state_comment | Synced | +---------------------------+-------------+ mysql -e "show status like 'wsrep_cluster_size'" +---------------------------+-------------+ | Variable_name | Value | +---------------------------+-------------+ | wsrep_cluster_size | 2 | +---------------------------+-------------+ mysql -e "show status like 'wsrep_local_state_comment'" +---------------------------+-------------+ | Variable_name | Value | +---------------------------+-------------+ | wsrep_local_state_comment | Initialized | +---------------------------+-------------+
以上试验说明采用了仲裁节点后,因为集群节点数变为了奇数,有效地避免了脑裂,同时将真正有故障的节点隔离出去了。
参考 https://jeremyxu2010.github.io/2018/02/mariadb-galera-cluster%E9%83%A8%E7%BD%B2%E5%AE%9E%E6%88%98/
https://mariadb.com/kb/en/library/getting-started-with-mariadb-galera-cluster/#bootstrapping-a-new-cluster